
Projects
Numeracy Investigation in Text-to-Text Transfer Model
Spring 2021
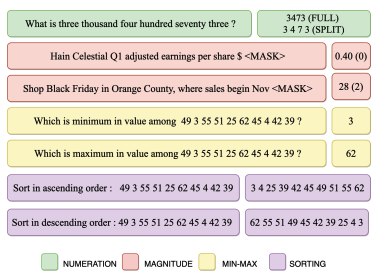
The transformer-based pre-trained language models often struggle in numerical understanding. Some possible reasons can be the tokenizers and pre-training objectives which are not specifically designed to learn and preserve numeracy. Here we investigate the ability of text-to-text transfer learning model (T5), which has outperformed its predecessors in the conventional NLP tasks, to learn numeracy. We consider four numeracy tasks: numeration, magnitude order prediction, finding minimum and maximum in a series, and sorting. We find that, although T5 models perform reasonably well in the interpolation setting, they struggle considerably in the extrapolation setting across all four tasks.
BIOMEDICAL QA-NER WITH KNOWLEDGE GUIDANCE
SPRING 2021

We formulated NER task as multi-answer knowledge guided QA task. We use entity type definition and examples as external knowledge. This novel formulation (a) improved NER performance (b) reduced system comfusion by reducing to single entity class using B, I, O tags (c) enabled the models to jointly learn NER specific features across various entity types from a large number of publicly available datasets. We analyze the effect of each type of knowledge separately and compare among them. We also understand the model's behavior by visualizing model's attention layers.
COMMONSENSE REASONING WITH IMPLICIT KNOWLEDGE
SPRING 2021
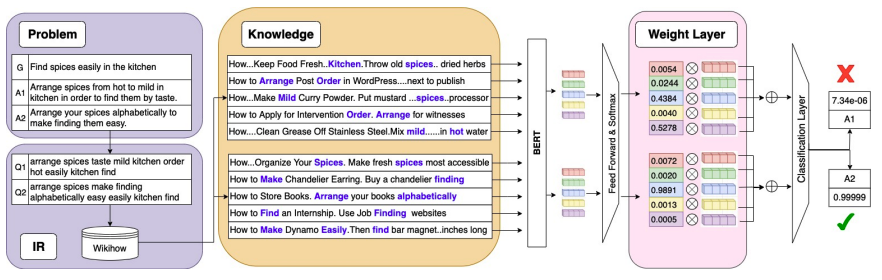
Commonsense Reasoning is a research challenge studied from the early days of AI. In recent years, several natural language QA task have been proposed where commonsense reasoning is important. There are two common - (i) Use of well-structured commonsense present in knowledge graphs, and (ii) Use of progressively larger transformer language models. While acquiring and representing commonsense in a formal representation is challenging in first approach, the second approach gets more and more resource-intensive. In this work, we take a middle ground where we use smaller language models together with a relatively smaller but targeted natural language text corpora. The advantages of such an approach is that it is less resource intensive and yet at the same time it can use unstructured text corpora which are abundant. We define different unstructured commonsense knowledge sources, explore three strategies for knowledge incorporation, and propose four methods competitive to state-of-the-art methods to reason with implicit commonsense.
FLOW-GRAPH FROM PROCEDURAL CYBERSECURITY TEXTS
SPRING 2021
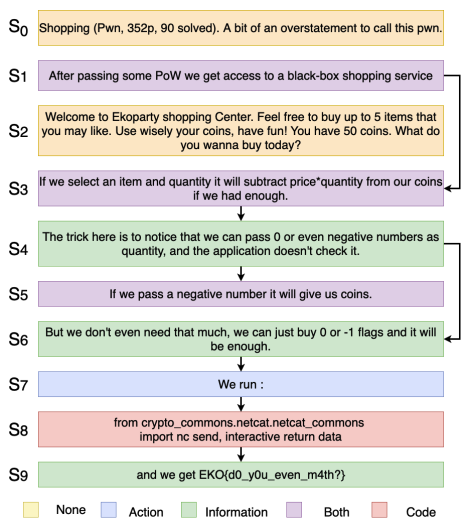
It is hard to follow the instruction flows from procedural natural language texts. Structured procedural texts can helps us to visualize intruction-flows, reason or build automatedd systems to assist novice agents to achieve a goal. Here we attempt to discover these intruction flows of actions and information from security instruction documents containing security vulnerability analysis experiences. We built an annotated large procedural dataset (3154 documents) from Catch-The-Flag competitions in cybersecurity domain. We propose two tasks - Sentence Type Identification and Flow Structure Identification. We show that our LM-GNN variants show good PRAUC and F1 scores across not only cybersecurity texts but also for cooking and maintenance manuals.
REASONING ABOUT EFFECTS OF ACTION
FALL 2020
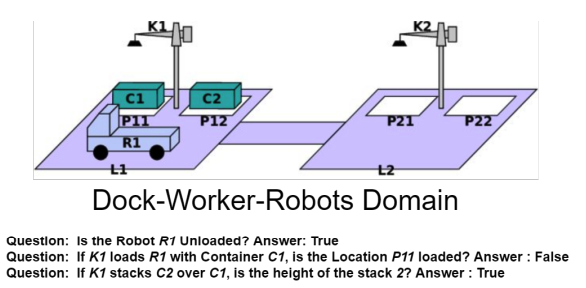
Reasoning about action and change has been the focus in Knowledge Representation from the early days of AI and more recently it has been a highlight in common sense question answering. Transformers have been shown to reason with facts and rules in a limited setting where rules are in natural language and represented as a conjunction of conditions. We here explore that can they reason in more complex scenarios. We start with Blocks-World domain and increase domain complexity to Logistics and Dock-Workers-Robots domains. We generated a fully-automated large QA dataset using Answer-Set Programming to simulated various scenarios in each of these domains. We show that in simpler domains transformers are able to achieve exceptional performance. As the domain complexity increases the performance decreases. We also show that transformers also show decent performance on each domain when transfer learned from generic domain.
OPEN BOOK QUESTION ANSWERING
NLP, FALL 2019
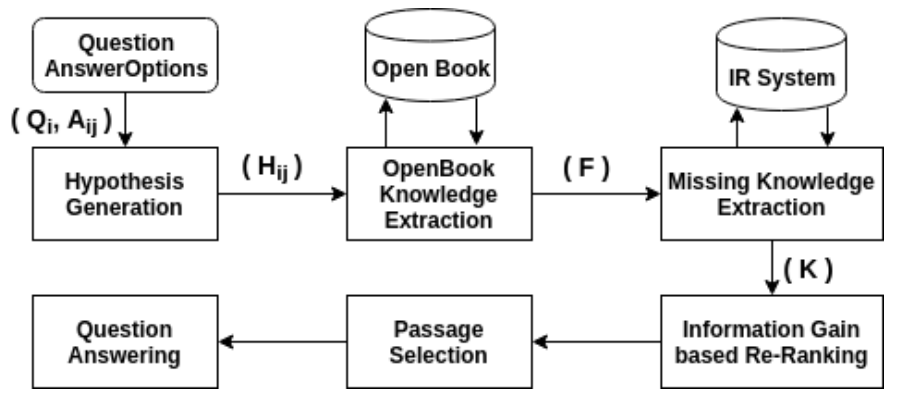
Open book question answering is a type of natural language based QA (NLQA) where questions are expected to be answered with respect to a given set of open book facts, and common knowledge about a topic. Recently a challenge involving such QA, OpenBookQA, has been proposed. Unlike most other NLQA tasks that focus on linguistic understanding, OpenBookQA requires deeper reasoning involving linguistic understanding as well as reasoning with common knowledge. In this paper we address QA with respect to the OpenBookQA dataset and combine state of the art language models with abductive information retrieval (IR), information gain based re-ranking, passage selection and weighted scoring to achieve 72.0% accuracy, an 11.6% improvement over the current state of the art.
CLINICAL SEMANTIC TEXTUAL SIMILARITY
NLP, SUMMER 2019

We used both statistical machine learning techniques like and simple deep learning techniques to establish semantic textual similarity in clinical domain. We used various features like Biomedical sentence embedding, BioSentVec (Cosine distance, Euclidean distance, Squared-Euclidean Distance, Correlation and Word-Mover distance), Token-level similarity (Jaccard (threshold of 0.7), Q-gram(q=2,3,4), Cosine, Dice, Overlap-based, Tversky Index, Monge-Elkan, Affine, Bag-Distance, TF-IDF, Editex, Levenstein, Needleman-Wunsh and Smith-Waterman similarity both for the given sentence pairs and also for the modified sentences having a common prefix), Numerical similarity using 200-dimension BioWordVec5 model, Natural language inference-based(NLI) features and Clinical concepts similarity using Metamap
STATISTICAL MACHINE LEARNING, SPRING 2019
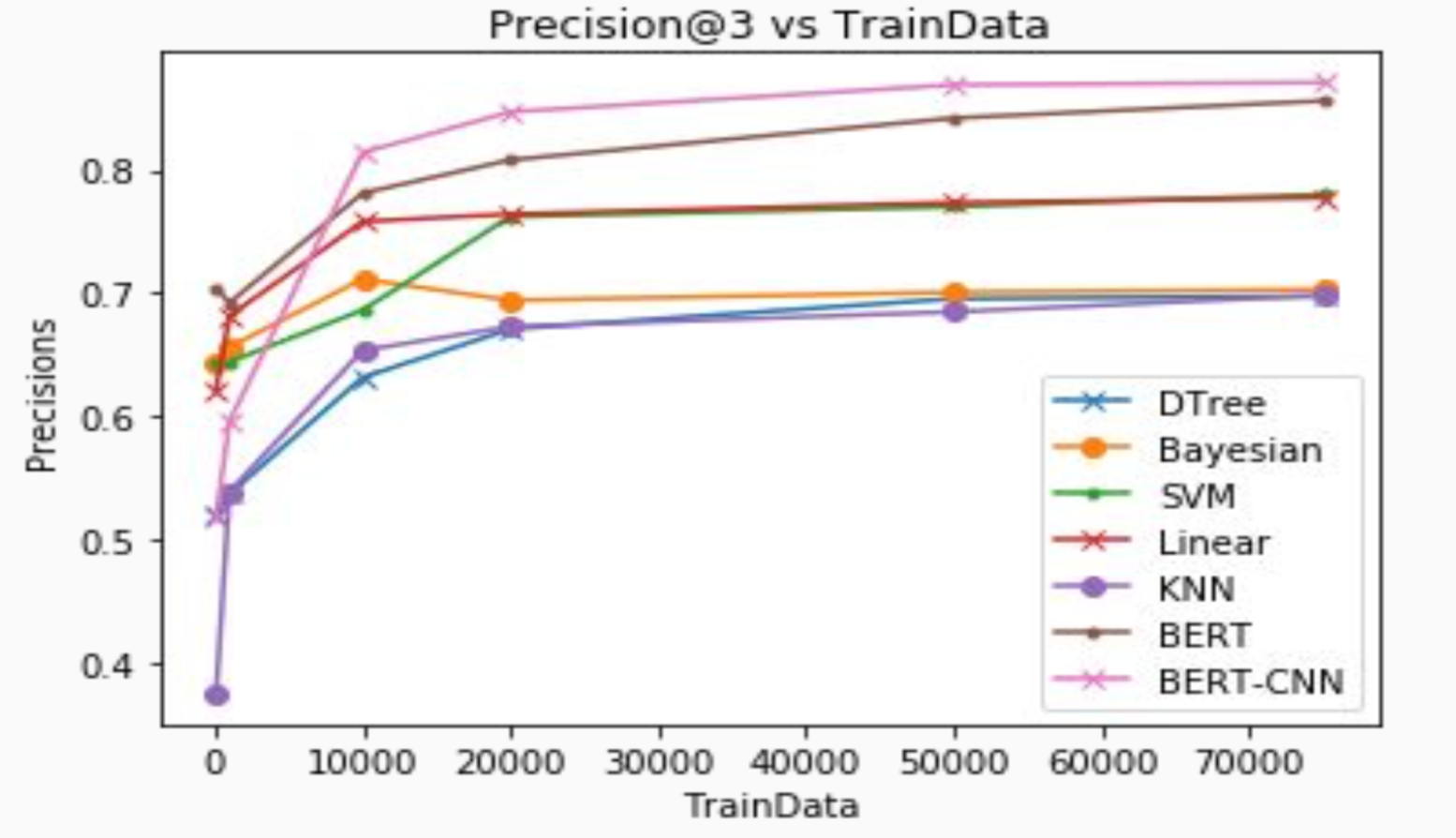
Information Retrieval (IR) and Knowledge Extraction(KE) is a core component for many NLP Tasks. Especially in Open Domain Question Answering (QA), we need to choose among very similar knowledge sentences. The knowledge sentences need to be relevant and not redundant. In this project, we improved the IR and KE for an application task of OpenBook QA. With improved KE, we also improve on OpenBook QA accuracy. A comprehensive analysis of Linear models(Logistic Regression, Perceptron, Passive-Aggressive Classifier, SGD), tree-based(Decision-Tree, Random-Forest, Extra-Tree), Support Vector Machines(Linear, Polynomial, RBF, Sigmoid), Naive-Bayes(Gaussian, Multinomial, Bernoulli), Feed-Forward Neural Network, Deep-Learning models(BERT, BERT-CNN) has been done on IR task.
ACTIVITY CLASSIFICATION USING GESTURE CONTROL ARMBAND
MOBILE COMPUTING, SPRING 2019
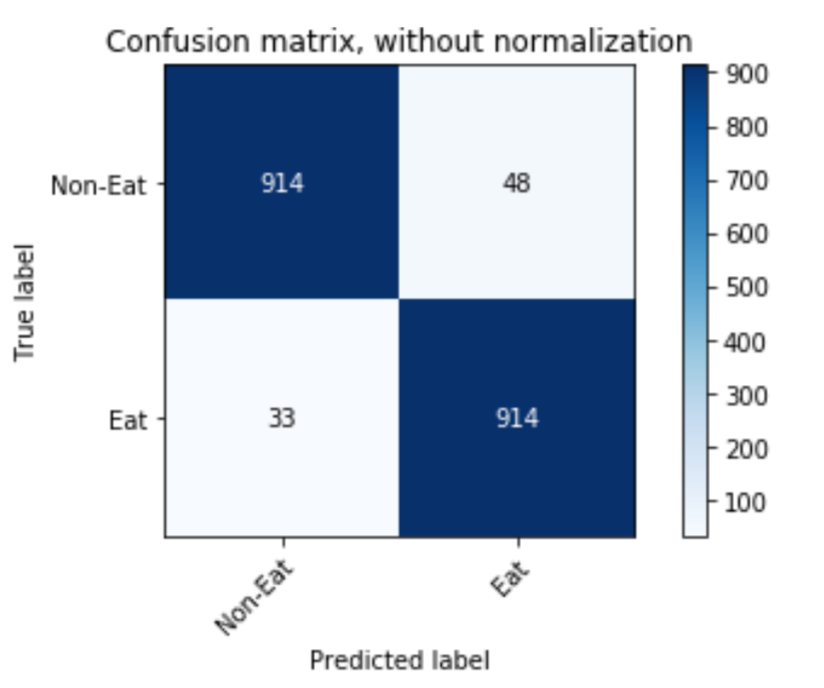
Eating activity recognition from data collected using Myo Gesture control Armband using machine learning and deep learning techniques like SVM, Random Forest, XgBoost, LightGBM, Logistic regression, Gaussian Process classifier, LSTM, Attention-based Conv-LSTM. The Inertial Measurement Unit(IMG) and Electromyography(EMG) features are collected wearing the band for 2 days and recording the time of eating by 4 students. We were able to distinguish between eating and non-eating activities with an accuracy of 94.76%
PERSONALITY PREDICTION OF FACEBOOK USERS FROM THEIR POSTS
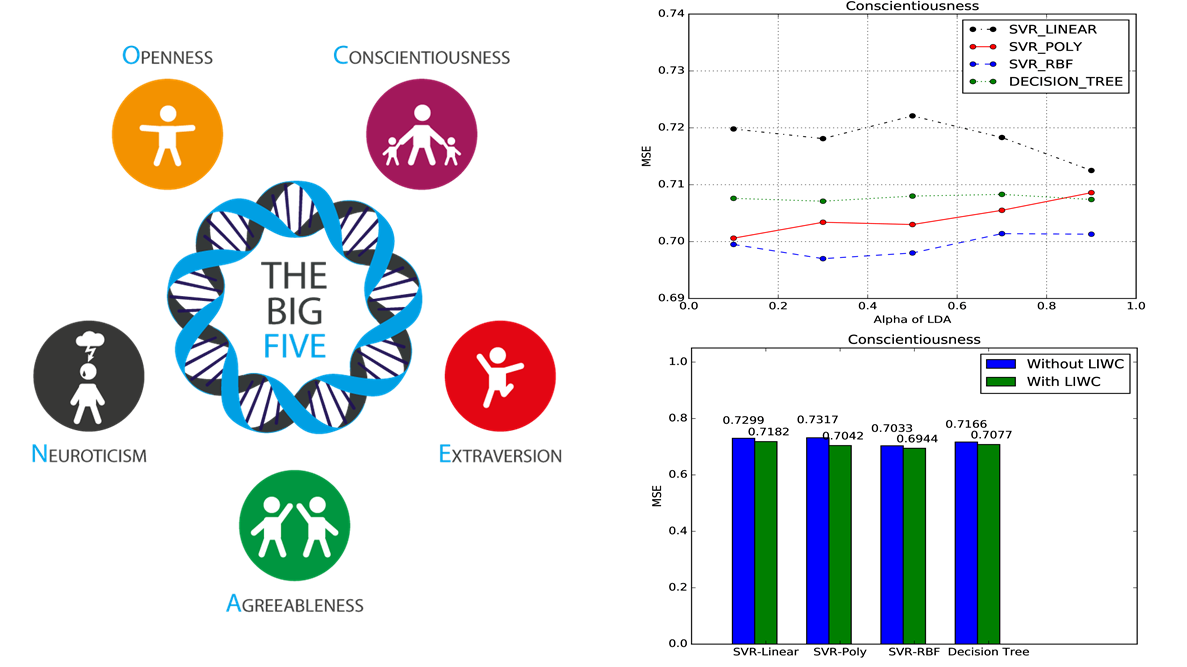
Can we predict the BIG5 personality traits of a user of Facebook directly from the social footprint that they leave on social media, i.e. their posts ? We used Latent Dirichlet Allocation(LDA) on the Facebook statuses from myPersonality dataset, to extract latent topics. Can we improve the personality prediction performance by adding other linguistic features ? We used machine learning approaches like SVR with linear, polynomial and RBF kernels along with Decision tree techniques have been used to predict BIG5 personality of users. Finally, a comparative analysis of each techniques is done for prediction using only Facebook statuses and statuses along with other linguistic features.
IMAGE CLASSIFICATION

Object classification on various datasets like CIFAR10, CIFAR100 and PASCAL VOC 2012 using Nearest Neighbor, k-Nearest Neighbor, Feed-Forward Neural Networks and Convolutional Neural Networks. Studied the impact of multiple activation functions on image classification. Comparison analysis of image preprocessing techniques like PCA, mean-normalization, standardization.
COMPONENT-BASED IMAGE APPROXIMATION SEARCH

Motivation is to search images based in how inter-related two images are, if we compare their components. A picture having a number of birds is far more related to a picture having a few birds and an animal than a third picture with cars along with few birds as all components of the first two images are living beings. A given composite image (with multiple objects) is searched among a set of other composite images and ordered based on how closely related it is with the images of the set. The top-most image in the ordering indicates the closest image to the given image. For component detection, selective search with fast non-maximal suppression has been used with ZCA normalization. The Convolutional neural network (CNN) have been used for the identification of the components. This can be used to find similarity among images which is difficult to find in conventional image search methods.
HEAD POSE DETECTION USING HOG

Histogram of Gradient(HOG) features used to detect and classify faces in Images and Video. The motivation for this project is head pose detection in the driver safety program. Here HOG features have been used with SVM to classify images of Pointing04 dataset into different head position classes. The classifier has been evaluated using error-rate, precision, recall, specificity, prevalence and F1-scores. For the second part of the project the head position of an individual have been tracked throughout videos using these hog features.